Instance Types and Pricing
What is an On-Demand instance?
What is an On-Demand instance?
What is a Spot instance?
What is a Spot instance?
How will I be charged for GPU instances?
How will I be charged for GPU instances?
Cloud Providers and Infrastructure
Which cloud provider do you support?
Which cloud provider do you support?
How long does it take for instances to launch?
How long does it take for instances to launch?
Is there an SLA or guaranteed uptime for my instances?
Is there an SLA or guaranteed uptime for my instances?
Data Management and Storage
How can I pause or stop my running instance without terminating it?
How can I pause or stop my running instance without terminating it?
How do I ensure my data persists after pausing or restarting an instance?
How do I ensure my data persists after pausing or restarting an instance?
/workspace directory. Note that this only works when pausing an instance - if you terminate the instance, all data will be lost. Always back up critical data to external storage (e.g., S3) before terminating or pausing.Can my data be recovered once I've terminated my instance?
Can my data be recovered once I've terminated my instance?
Can I get very large storage volumes (multi-terabyte)?
Can I get very large storage volumes (multi-terabyte)?
Configuration and Connectivity
Can I specify custom hardware configurations such as CPU, RAM, or disk size?
Can I specify custom hardware configurations such as CPU, RAM, or disk size?
I'm having trouble connecting via SSH or Jupyter. How do I fix connection issues?
I'm having trouble connecting via SSH or Jupyter. How do I fix connection issues?
chmod 400 private_key.pem. For Jupyter notebooks, simply click the provided link on your instance page to access the notebook interface directly in your browser. If you still face issues, contact support with error details.How can I see which ports are open on my instance?
How can I see which ports are open on my instance?
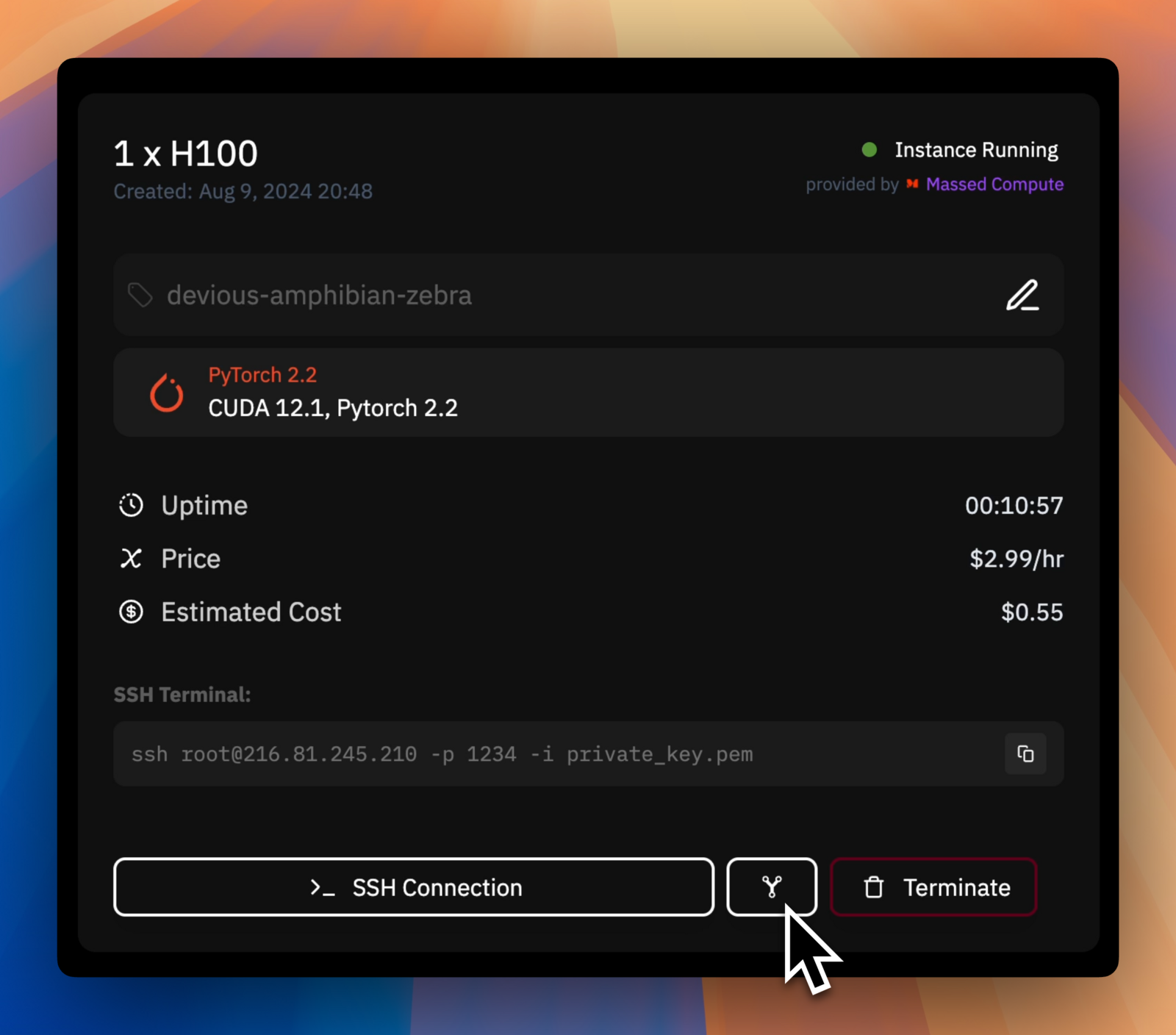
Can I open custom ports or host a service accessible over HTTP/HTTPS on my instance?
Can I open custom ports or host a service accessible over HTTP/HTTPS on my instance?
Can I bring my own Docker image or custom environment?
Can I bring my own Docker image or custom environment?
Can I run Docker or other system services on my instance?
Can I run Docker or other system services on my instance?
docker-in-docker configurations and system-level services, while others do not. Check the provider’s documentation or contact support if you encounter issues. We’re working on better clarifications and tutorials to help you understand what’s supported in your chosen environment.Billing and Payments
Is there a way to get a refund if my instance fails or I'm overcharged?
Is there a way to get a refund if my instance fails or I'm overcharged?
How do I apply a promotional code to get credits?
How do I apply a promotional code to get credits?
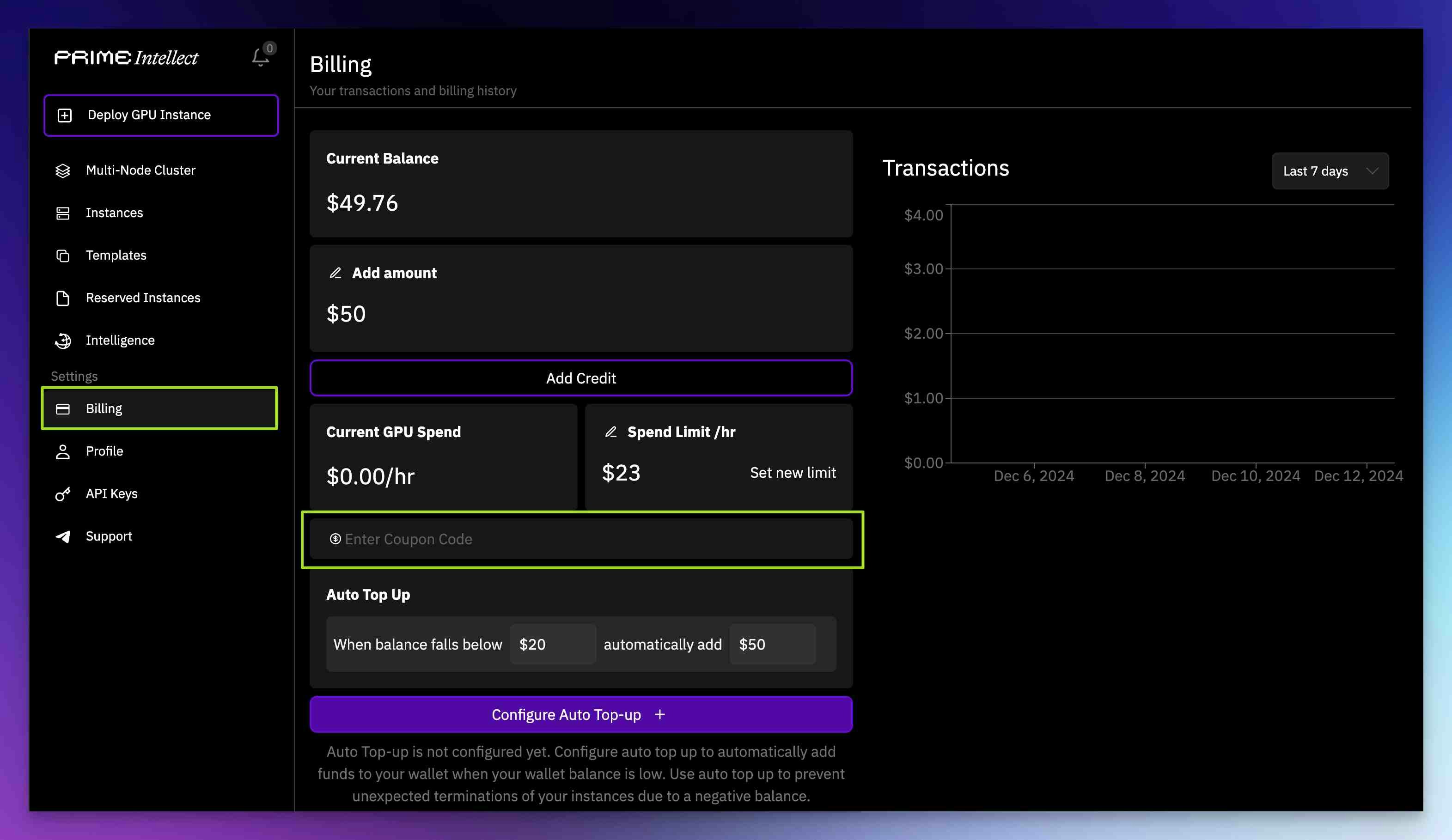
How do I set up team accounts or custom billing emails for invoicing?
How do I set up team accounts or custom billing emails for invoicing?
Can I pay in other currencies or use alternative payment methods?
Can I pay in other currencies or use alternative payment methods?
Troubleshooting
My instance won't start or is stuck in 'pending.' What should I do?
My instance won't start or is stuck in 'pending.' What should I do?
Multi-Node Cloud
What is a Multi-node instance?
What is a Multi-node instance?
- 3.2Tbps INFINIBAND connectivity
- 104 CPU cores per node
- 16TB storage per node
- ~$52.80/hr
- 100Gbps ETHERNET connectivity
- 104 CPU cores per node
- 12TB storage per node
- ~$40.80/hr (CHEAPEST CLUSTER option)
How do I use one?
How do I use one?
Can I get reservations for longer durations?
Can I get reservations for longer durations?
GPU Providers
How do I become a GPU provider?
How do I become a GPU provider?