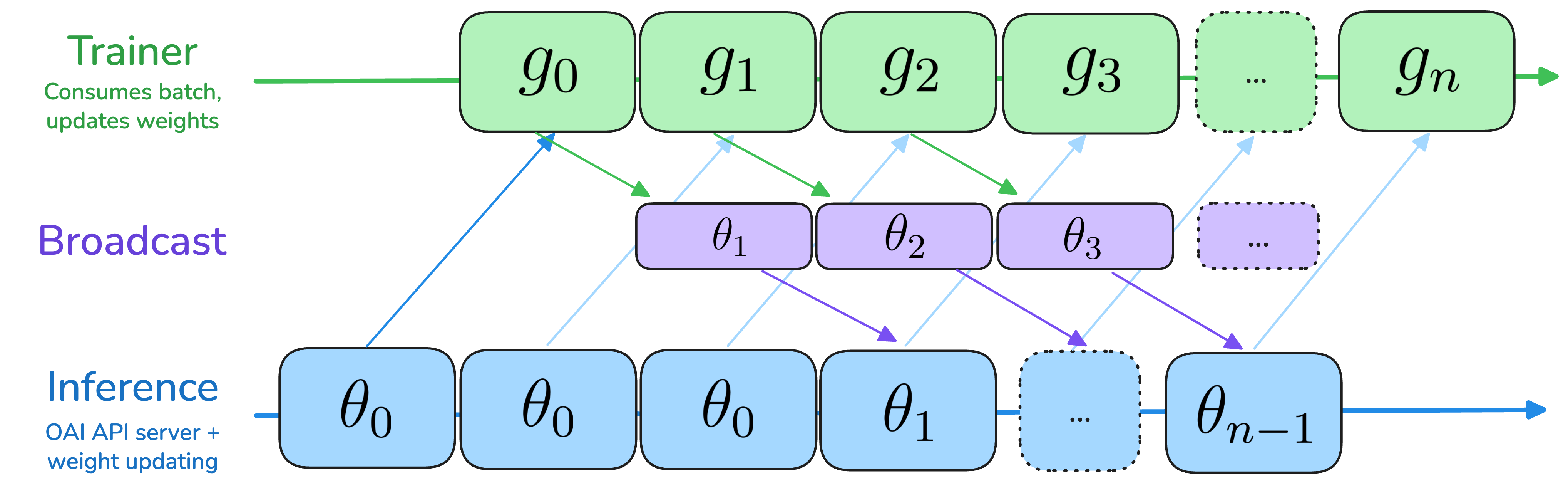
PRIME-RL implements asynchronous off-policy training, instead of the traditional synchronous on-policy training. This means that we allow inference to generate rollouts from a stale policy up to (in the code we call thisDocumentation Index
Fetch the complete documentation index at: https://docs.primeintellect.ai/llms.txt
Use this file to discover all available pages before exploring further.
max_async_level) steps ahead of the trainer. With k=1 and trainer and inference step timings being equal, this allows to run without any idle time on either the trainer or inference. By default, we set k=2 to allow overlap with a weight broadcast over the Internet, which is needed for decentralized training.
Loss Objective
We adopt a loss objective capable of handling the natural distribution shift caused by the off-policy nature of the training. By default, we use a token-level loss variant of the AIPO training objective introduced in Llama-RL, but omit the entropy and KL loss terms. At each step, we sample prompts from our dataset. For each prompt , we sample a group of rollouts and use a verifier to assign scores to each . Then, the optimization objective is given by where refers to the policy that generated the rollout, refers to the current policy, is the token-level advantage, and is the importance sampling clipping ratio.Step Semantics
PRIME-RL uses a global training step that is used to tag artifacts:- Trainer: Produces policy with weights from rollouts
- Inference: Produces rollouts from policy
max_async_level parameter, which defaults to 2. Note that we use 0-indexed steps to cleanly indicate that at each step, the divergence off-policy gap is at most steps.