Documentation Index
Fetch the complete documentation index at: https://docs.primeintellect.ai/llms.txt
Use this file to discover all available pages before exploring further.
RL
The main usecase of PRIME-RL is RL training. Three main abstractions facilitate RL training: the orchestrator, the trainer, and the inference service.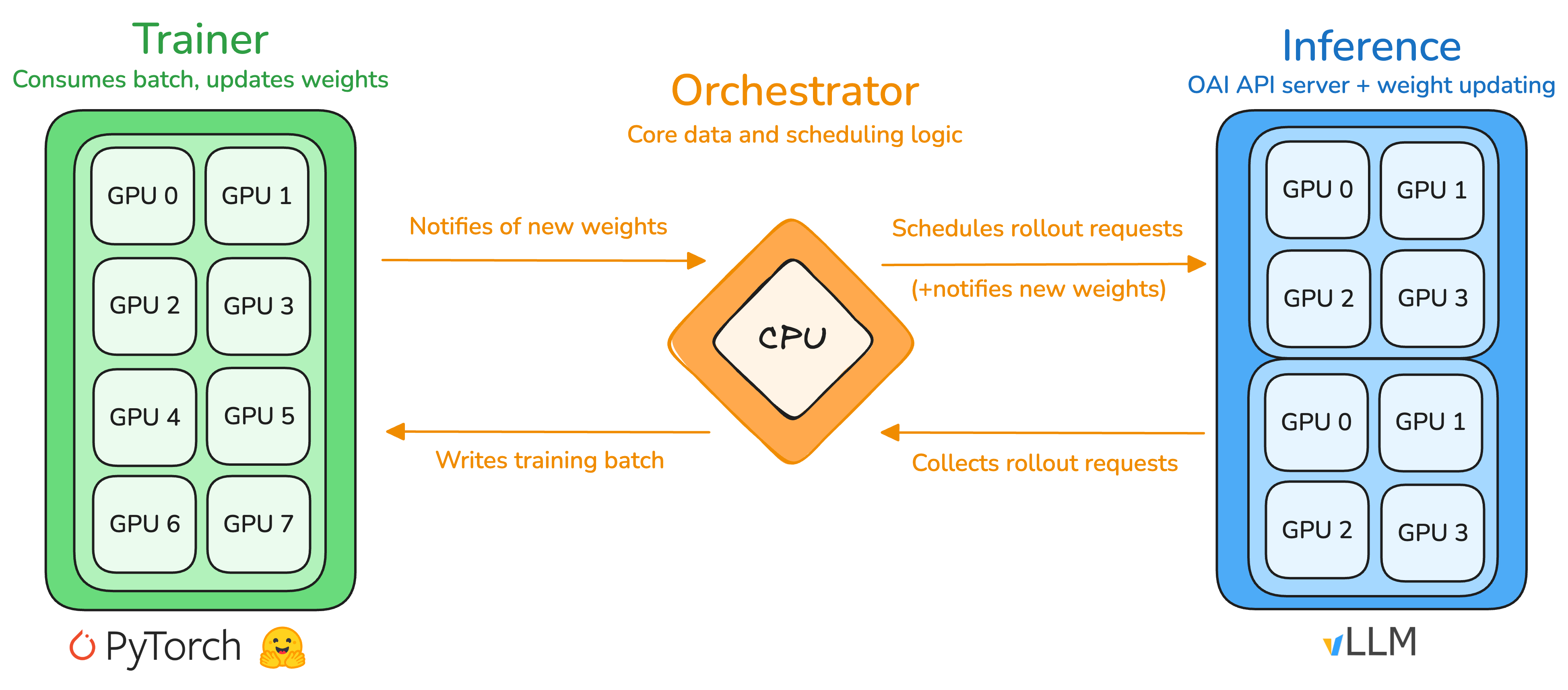
Orchestrator
The orchestrator is a lightweight CPU process that handles the core data and scheduling logic, serving as an intermediary between the trainer and inference service with bidirectional relays. In one direction, it collects rollouts from the inference server, assembles them into packed batches, and dispatches them to the trainer; in the other direction, it relays updated model weights from the trainer to the inference service. The orchestrator utilizesverifiers environments to abstract multi-turn rollout generation and scoring. Each training and evaluation environment is exposed as a vf.EnvServer as a sidecar to the orchestrator process (default) or as a standalone process (e.g. used in hosted training to run environments in containers).
Trainer
The trainer is responsible for producing an updated policy model given rollouts and advantages. We use FSDP2 as the backend with compatibility for any HuggingFace (HF) model. For some models we also provide custom implementations, mostly for performance reasons. FSDP shards model parameters, gradients, and optimizer states, allowing training large models with data parallelism and minimal GPU memory footprint. We support a variety of popular training objectives, such as GRPO, GSPO, OPO, RLOO and CISPO. The trainer is inspired bytorchtitan and relies on native PyTorch features to implement advanced parallelism techniques, such as tensor, context or expert parallelism.
Inference
The inference service in its simplest form is a standard OpenAI-compatible server with a vLLM backend. The API specification is extended with a customupdate_weights endpoint to reload model weights from a HF-compatible checkpoint on disk. Otherwise, we rely on vLLM’s optimized kernels, parallelism strategies, and scheduling for fast rollout generation. Given the disaggregated nature of the service architecture, it can be directly extended to include multiple engines with a shared request pool, allowing operation across multiple clusters and straightforward integration of alternative inference engines (e.g. SGLang, Tokasaurus). We also heavily rely on native data parallelism in vLLM (also available in SGLang) for orchestrating the fleet of nodes dedicated to inference.
RL
For doing RL training all components need to be started. One can do this manually:rl entrypoint to start all components.
uv run rl --help.
SFT
We provide a fairly straight-forward SFT trainer which is capable of fine-tuning any conversational model on multi-turn conversation with tool calling. It shares a lot of components with the RL trainer, such as the modeling code, parallelism techniques, checkpoint format, logger, etc. which ensures a seamless post-training workflow. To start an SFT training, you need to prepare a conversational dataset in either prompt-completion format or rawmessages format. If messages is provided, the trainer interprets the full conversation as a single sample with an empty prompt and applies role-based loss masking across the whole chat. If both messages and prompt / completion are present, messages takes precedence. Single-turn fine-tuning should be compatible with the chat templates of most models. However, to properly handle loss masking, we require that the tokenizer’s chat template satisfies a prefix property: the tokenization of any conversation prefix must be a prefix of the tokenization of the full conversation. For instance, tokenizing message 1 should yield a token sequence that forms a prefix of tokenizing messages 1 and 2, which in turn should be a prefix of tokenizing messages 1, 2, 3, and so forth. An example of a chat template that does not satisfy this property is Qwen3’s chat template, as it strips away past think sections.
On a single GPU, start the training with the sft entrypoint
torchrun with --nproc-per-node to start the training.
uv run sft --help.