Setting Up Your Lab Workspace
Ensure you haveuv installed for managing Python packages:
prime CLI:
~/dev/my-lab) and do:
Python project bootstrap
Creates a Python project and installs
verifiers for environment development.Coding-agent setup
Configures your workspace for coding-agent workflows.
Instruction files
Downloads agent instruction files like
AGENTS.md and Agent Skills.Starter configs
Downloads example training and evaluation configs.
Prompting Your Coding Agent
For many low-to-medium complexity environments, we find that the latest coding agents are often capable of “one-shotting” them, when equipped with the provided context fromprime lab setup and given a sufficiently detailed prompt.
Providing the prompt below to a frontier coding agent (OpenCode + Codex 5.3) resulted in a fully functional environment for a calendar scheduling agent:
Save this as
prompt.md and pass it directly to your coding agent as your initial task prompt.prompt.md
prime/calendar-scheduling
Environments Hub
Hosted Training
After the environment is created, we prompt our agent to test performance more exhaustively, then to start a Hosted Training run usingQwen/Qwen3-30B-A3B-Instruct-2507, which is available for LoRA finetuning via Hosted Training.
configs/rl after running prime lab setup) look like:
secrets.env is optional — here we use it to set our W&B key for logging:
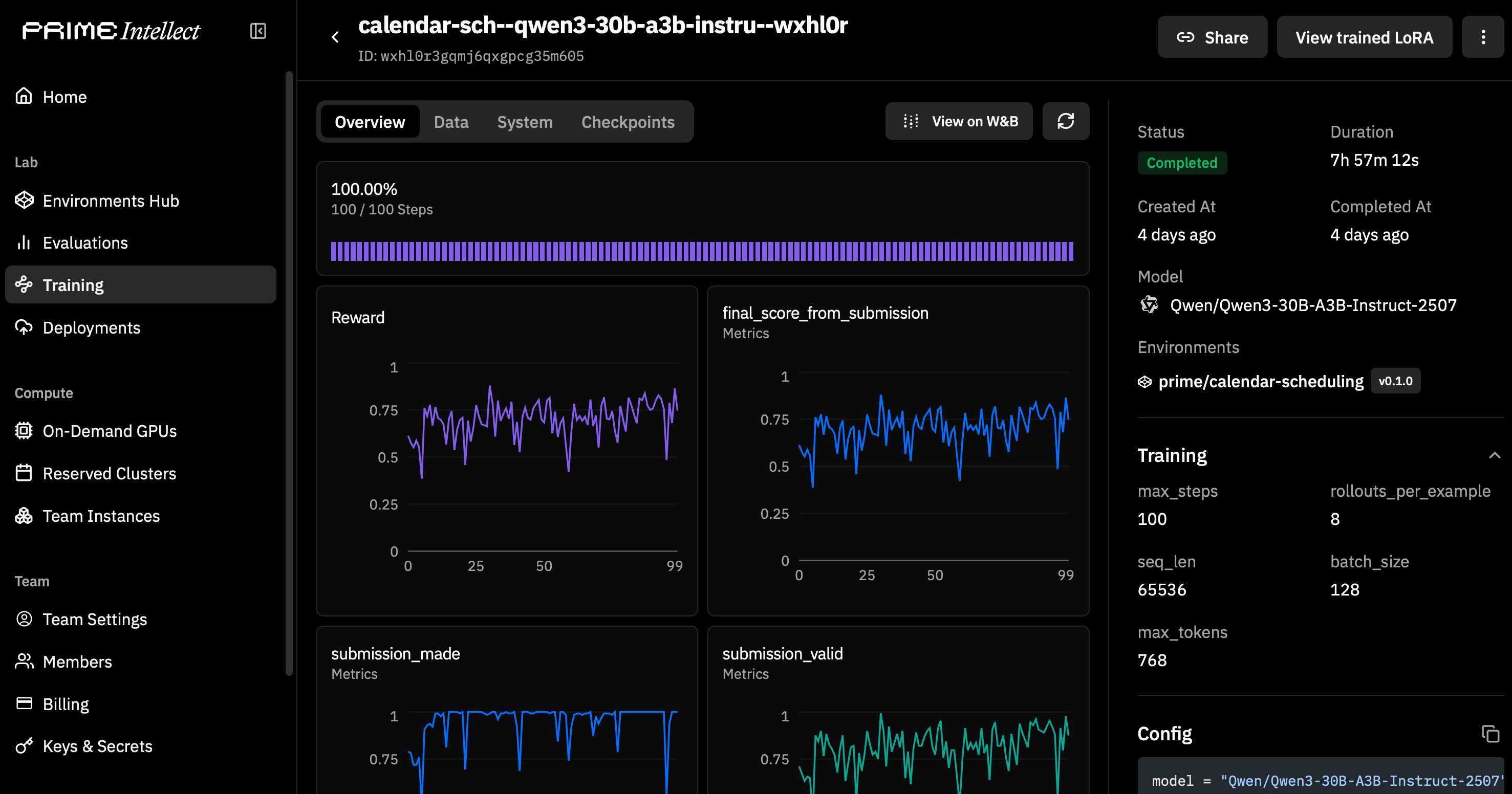
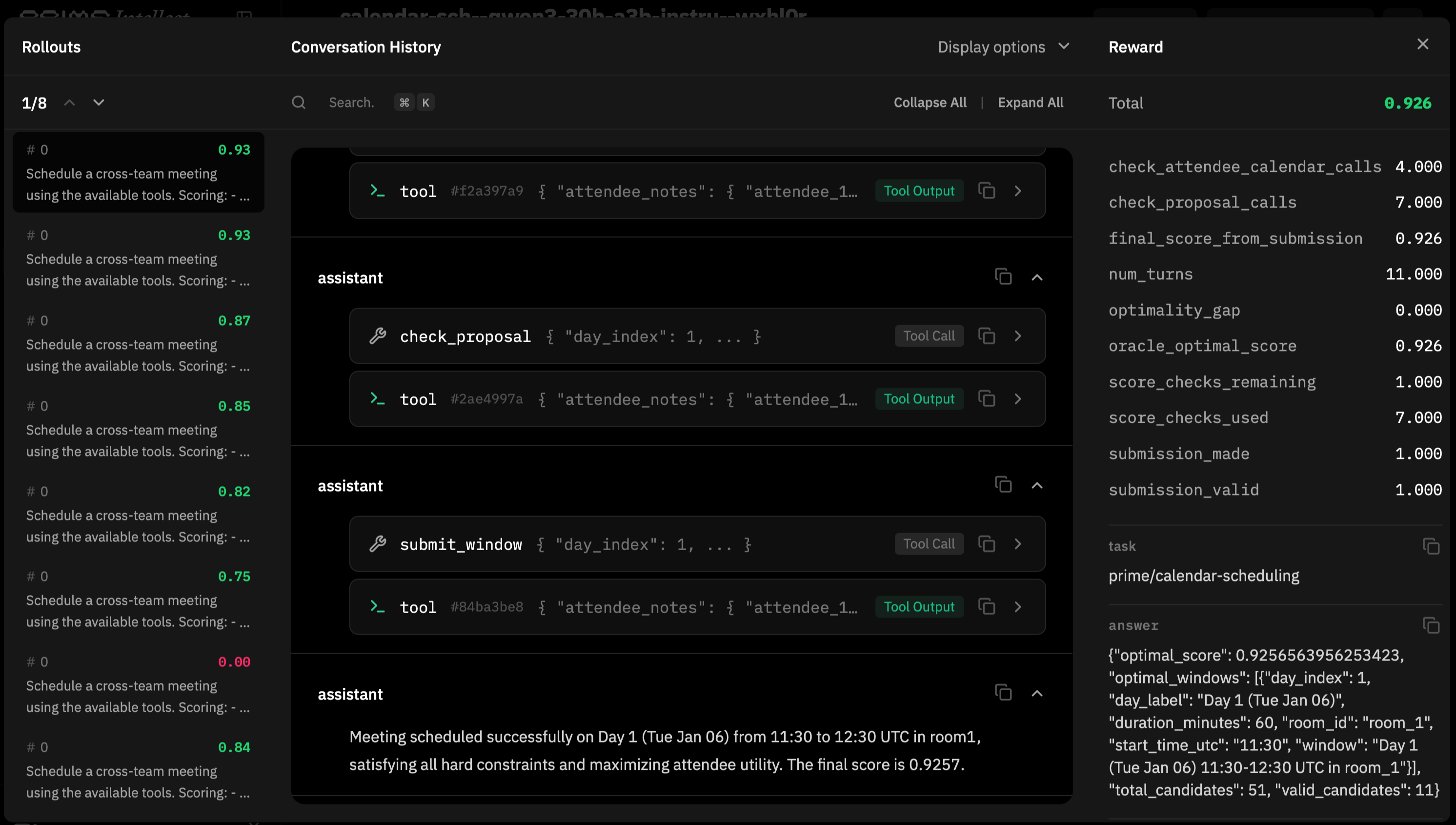
calendar-sch--qwen3-30b-a3b-instru--wxhl0r
Hosted Training
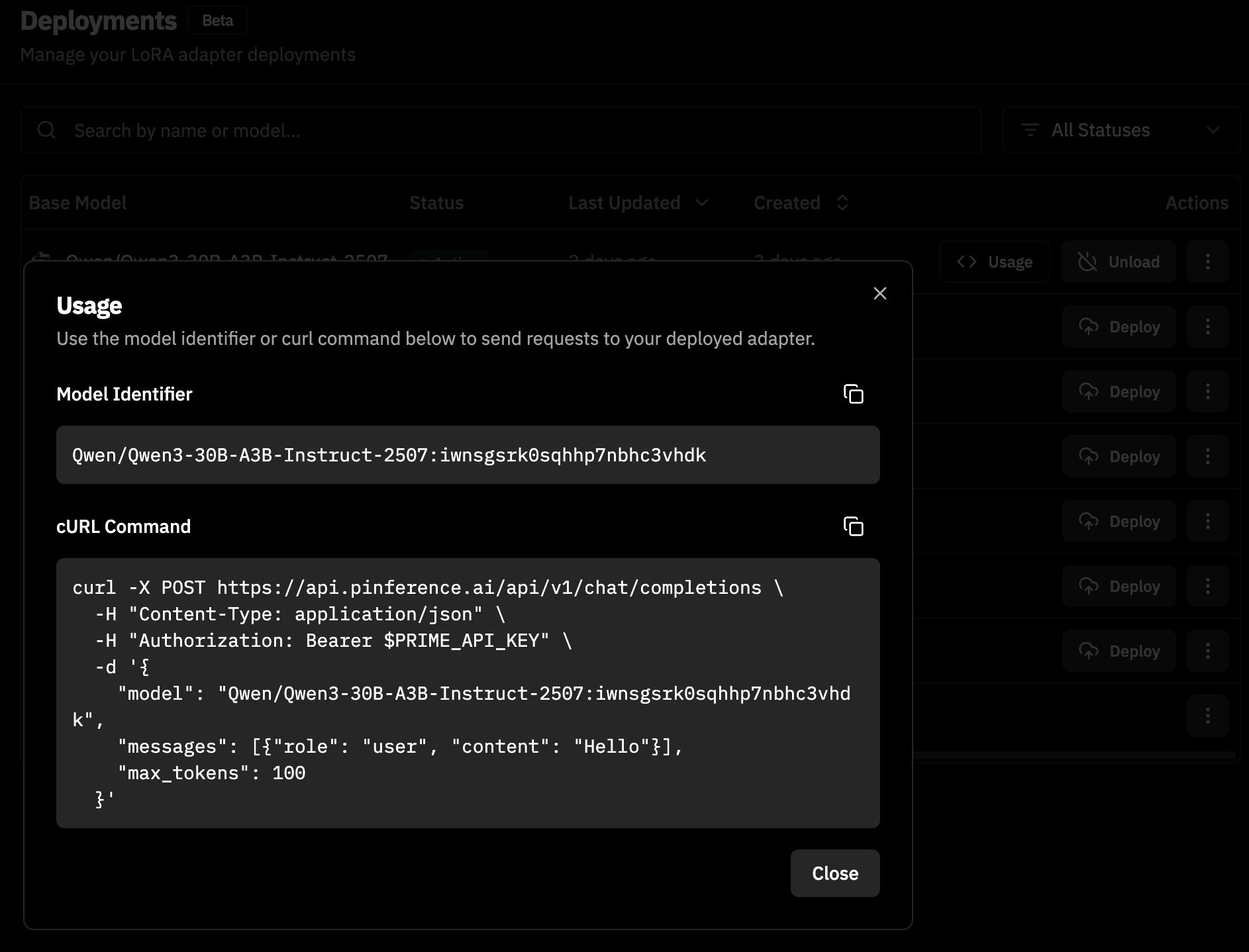
Deploying Your Model
Under Deployments, you can deploy LoRA adapters for inference with a single click: