prime eval run --hosted.
What hosted evaluations are for
Use hosted evaluations when you want Prime to handle the execution environment for you:- Run a published environment without setting up local Python dependencies
- Evaluate large jobs against a Hub environment slug
- Monitor logs remotely and share runs through the platform
- Grant temporary sandbox, instance, or tunnel permissions for tool-using environments
Hosted evaluations require an environment that is already published to the Environments Hub. If you only have a local environment, push it first with
prime env push.Prerequisites
Before running a hosted evaluation, make sure you have:- A published environment on the Environments Hub
- Write access to that environment
- Prime CLI installed and authenticated if you plan to use the CLI flow
- Billing configured for your chosen inference path
- Prime account balance if you are using Prime Inference
- Or an external provider API key if you are using
--api-base-urlwith a custom OpenAI-compatible endpoint
Quick start with the CLI
The new hosted eval flow is built intoprime eval run.
Follow logs until completion
--follow, the CLI keeps polling the run, streams hosted logs, and exits when the evaluation reaches a terminal state.
Run from a TOML config
Hosted evals also support TOML configs.Use a custom OpenAI-compatible endpoint
Hosted evaluations can also run on Prime-managed infrastructure while sending model requests to your own OpenAI-compatible endpoint.--api-key-var to name the environment variable that contains your provider key inside the hosted sandbox. Then provide that secret either through the environment’s stored secrets or with --custom-secrets for a one-off run.
--api-base-url only changes the inference endpoint. The environment still runs inside a Prime-hosted sandbox.Hosted-only CLI options
These flags only apply when you pass--hosted:
Example: Environment Args and Custom Secrets
--custom-secrets for run-specific values. Secrets already configured on the environment continue to work as usual.
Hosted eval
env_args are passed to load_environment(), similar to training [[env]].args. Use them for custom environment settings such as split, difficulty, tool configuration, or other environment-specific overrides supported by your environment.Monitoring and managing hosted runs
After starting a hosted evaluation, the CLI prints the evaluation id and platform URL.--follow only streams logs and waits for completion. Hosted evaluations do not yet have a training-style checkpoint or restart workflow.List evaluations
HOSTED and LOCAL evaluations.
Inspect one run
Stream logs for an existing hosted run
Stop a running hosted evaluation
Running a hosted evaluation from the dashboard
You can still launch the same workflow from the Environments Hub UI.Step 1: Open the environment
- Go to the Environments Hub
- Open your environment
- Go to the Evaluations tab
- Click Run Hosted Evaluation
Step 2: Choose a model
Select an inference model for the run.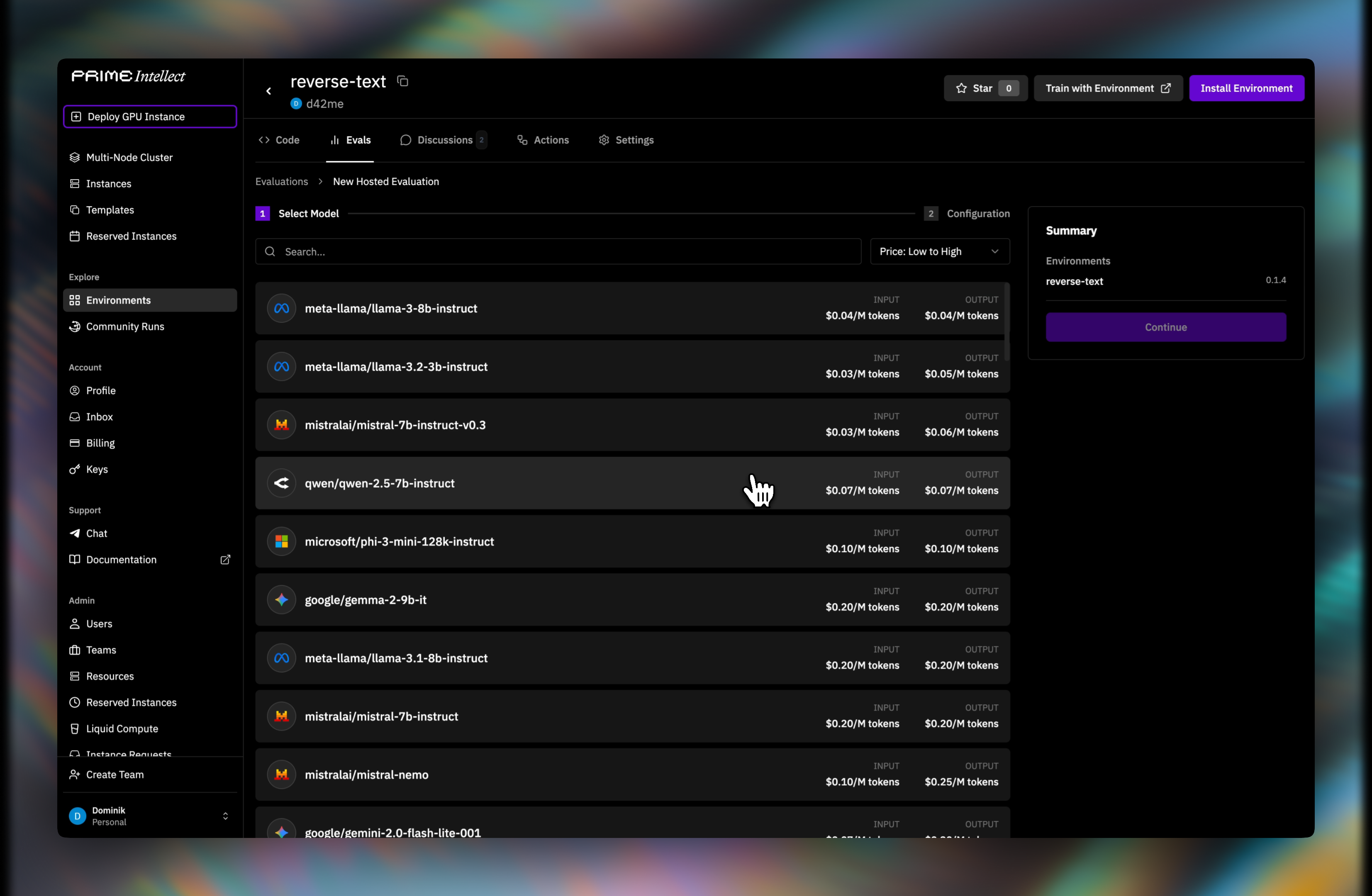
Step 3: Configure the run
Set the number of examples, rollouts per example, and any environment arguments.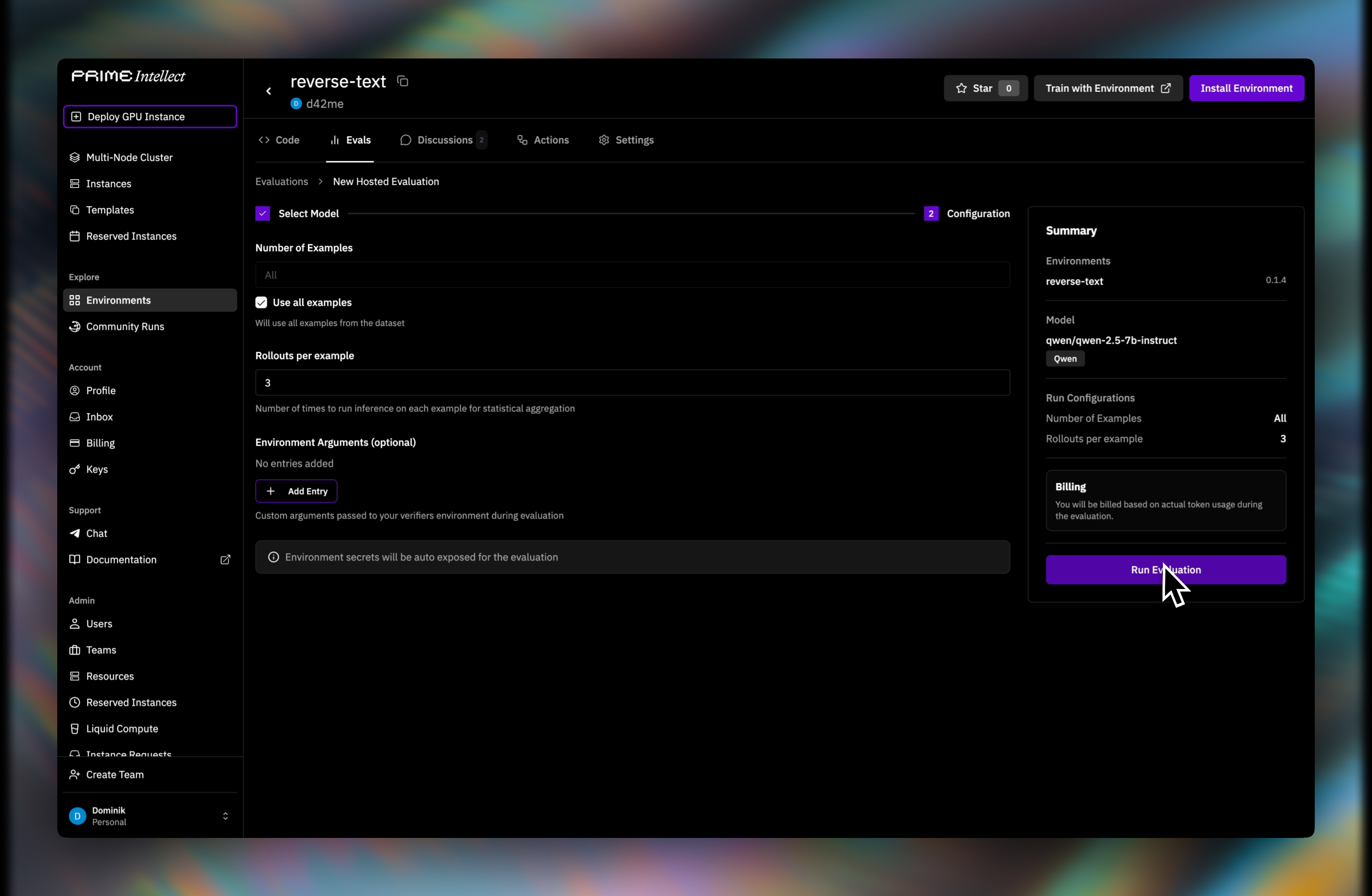
Environment secrets linked in the Hub are exposed automatically during hosted evaluation runs. You only need
--custom-secrets when launching a CLI run with additional per-run secrets.Step 4: Monitor progress
You will be redirected to the evaluations list where you can watch the run status.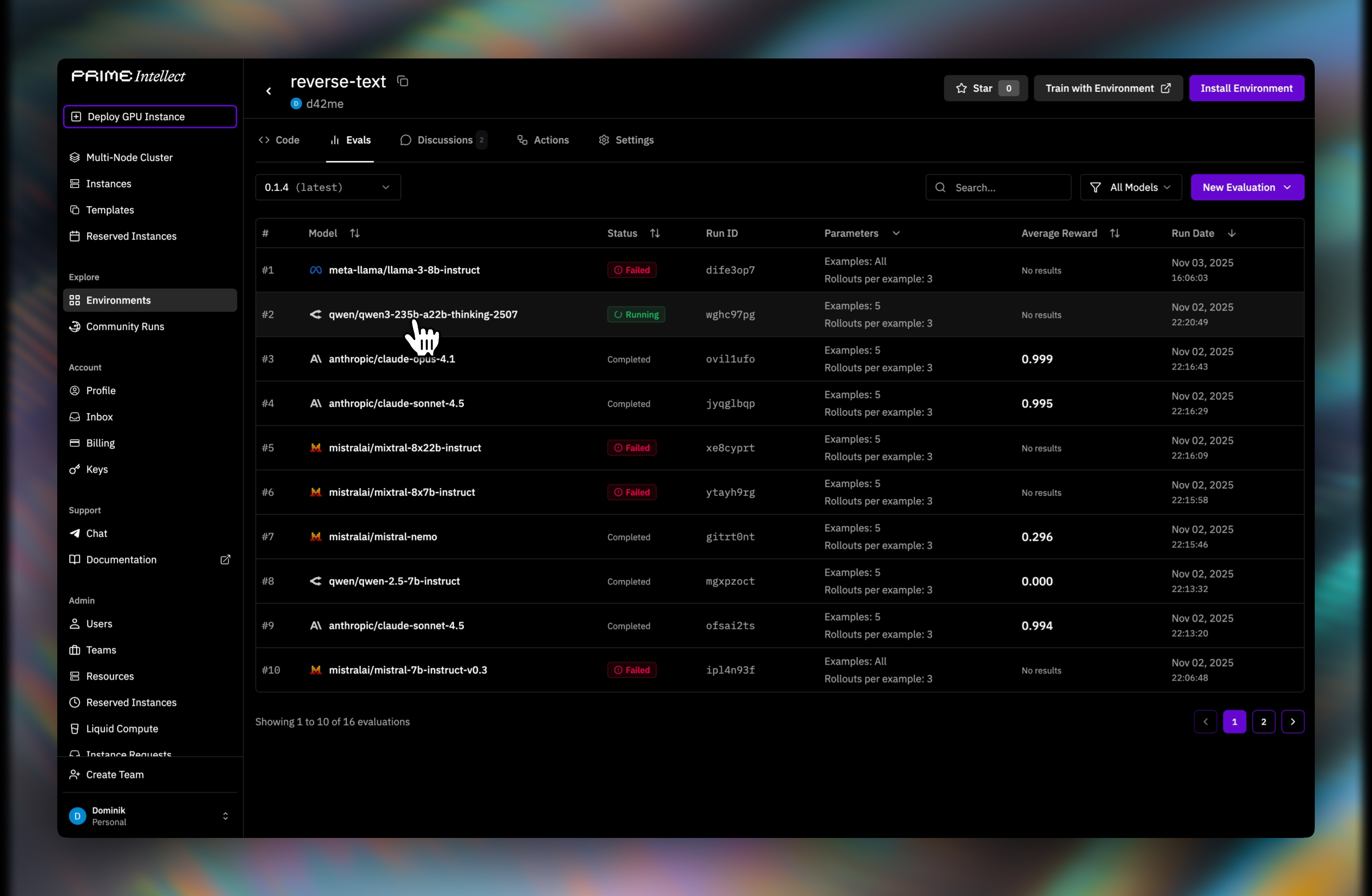
Step 5: Review results
Completed runs show aggregate metrics and per-sample outputs in Prime Evals.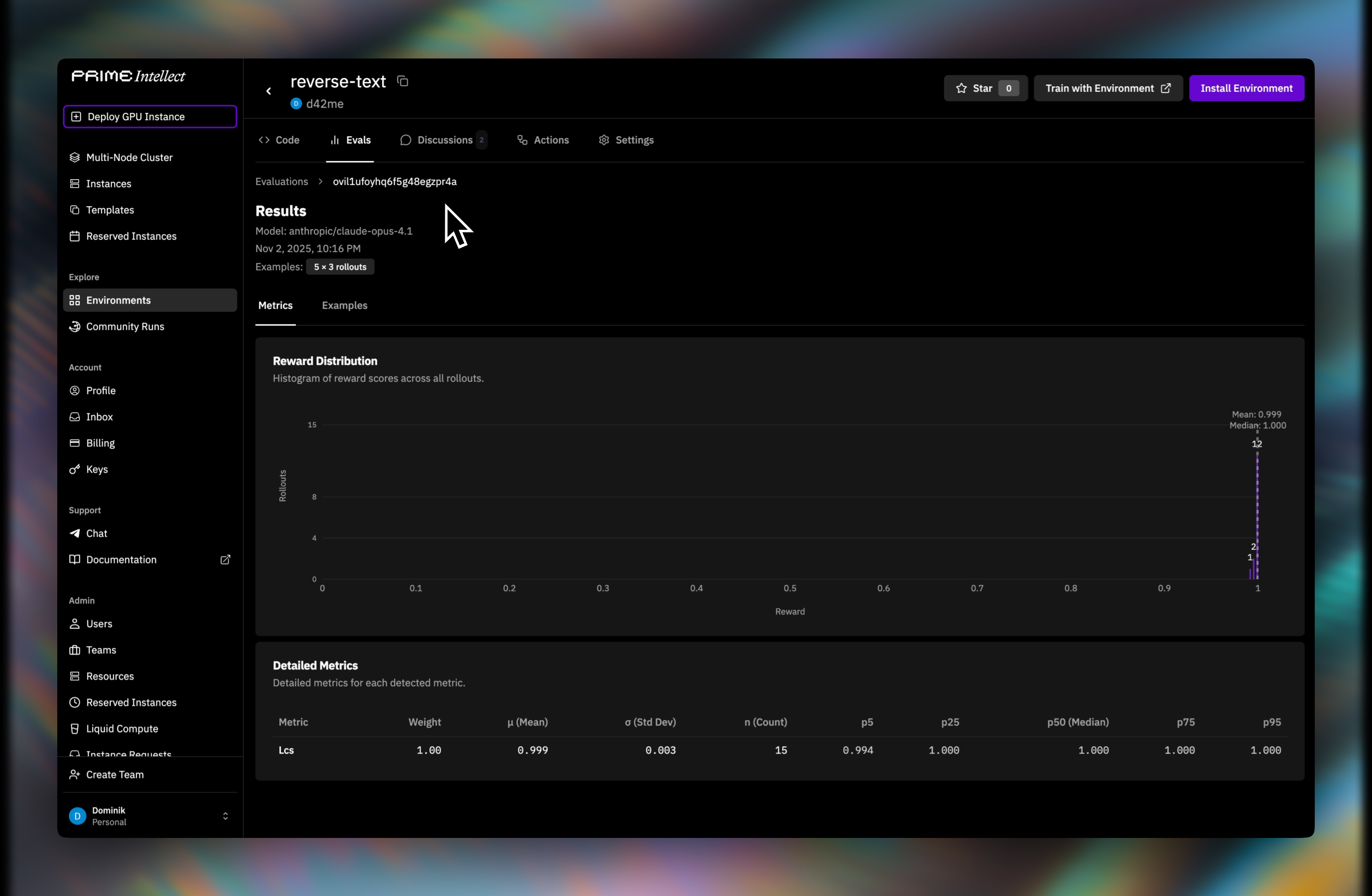
Failure modes
When a hosted evaluation fails, the platform surfaces the error message and logs. Common causes:- Environment code errors — import failures, dependency issues, invalid verifier logic
- Missing permissions — the run needs sandbox, instance, or tunnel access but those flags were not enabled
- Missing secrets — environment-linked or custom secrets were not available
- Timeouts — the run exceeded the configured or platform timeout
- Inference issues — temporary provider or model errors
Pricing
Hosted evaluations support two billing modes:- Prime Inference (default) — If you do not pass
--api-base-url, the run uses Prime Inference pricing for the selected model. The hosted evaluation sandbox runtime is not billed separately. - Custom OpenAI-compatible endpoint (CLI/API) — If you pass
--api-base-url, the hosted evaluation is billed as sandbox compute on Prime while your external provider bills model tokens directly. In this mode you must provide the provider key through an environment secret or--custom-secrets.
- The selected model or endpoint pricing
- Prompt and completion token usage
num_examples × rollouts_per_example- Any extra tool usage triggered by the environment
When to use dashboard vs CLI
- Use the dashboard when you want the simplest point-and-click flow
- Use the CLI when you want reproducible commands, TOML configs, log following, or automation in scripts/CI