prime-rl is a framework for large-scale, asynchronous reinforcement learning of large language models. It is designed to be easy to use and hackable, yet capable of training 1T+-parameter MoE models on 1000+ GPU clusters.
Architecture
Aprime-rl RL run is three cooperating processes:
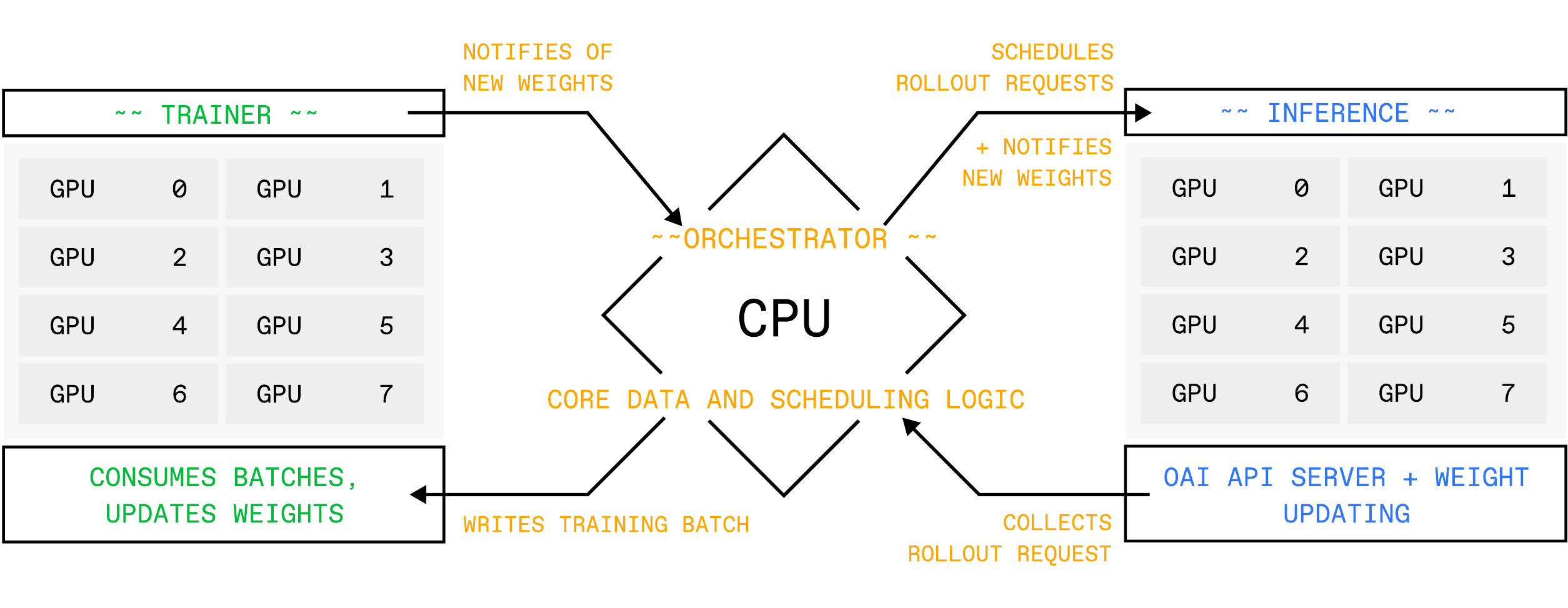
- Inference — vLLM-backed server (or fleet) holding the current policy. The orchestrator drives rollouts through the token-in
/inference/v1/generateroute via therendererspackage (OpenAI-compatible chat/completions routes are also exposed for external clients). We are trying to stay up-to-date with the latest vLLM features, you can read more about the supported features and deployment options in the dedicated inference documentation. - Orchestrator — Lightweight CPU process that owns the data plane across many
verifierstraining and eval environments. Each env runs in an isolated subprocess with a variable-size pool of env workers for scalability. The orchestrator drives multi-turn rollouts against the inference fleet (tool use, browsers, sandboxes, long horizons) without re-tokenizing across turns, computes advantages, packs the rollouts into training batches, and relays new weights from trainer to inference. - Trainer — FSDP2 process group that consumes packed rollouts and steps the optimizer. We ship optimized custom modeling code for many MoE / dense / VLM families that unlocks advanced trainer parallelism — expert parallelism (EP, with DeepEP kernels) and context parallelism (CP) for long-sequence training — plus selective activation checkpointing, FP8 training on Hopper+, LoRA, and multi-tenant training (many concurrent LoRA tenants sharing one trainer + inference deployment). You can read more in the dedicated training documentation.
Installation
verifiers / renderers / research-environments submodules, installs uv, and runs uv sync --all-extras. For manual setup, or troubleshooting, see the README.
You need at least one NVIDIA GPU (RTX 3090/4090/5090, A100, H100, H200, or B200). Single-GPU runs are supported for debugging; production RL is typically 1× inference node + 1+ trainer nodes.
Quick Run
Train an SFT-warmedQwen3-0.6B on the reverse-text task — the env is bundled with the verifiers submodule so no separate install is needed. This config ships in the repo and runs on two GPUs (one for inference, one for the trainer):
rl entrypoint reads examples/basic/reverse-text/rl.toml, splits it into per-process sub-configs, picks GPU 0 for inference and GPU 1 for the trainer, launches all three processes, and tees their stdout into outputs/logs/{trainer,orchestrator,inference}.log. Within a minute the trainer should log step 1 and a reward sample; after 20 steps the run completes and final HF-compatible weights land at outputs/weights/step_20.
Documentation
- Configuration — TOML composition, CLI overrides, dry-run.
- Training — Launch and observe RL and SFT runs.
- Inference — vLLM-backed server (or fleet) holding the current policy.
- Scaling — Single-GPU through multi-node clusters via FSDP / EP / CP and SLURM.
- Algorithms — Async semantics, loss / advantage / filter plugins, trajectory merging.
- Advanced — Custom modeling, multimodal, LoRA, multi-tenant, P/D inference.
- Development — Test suite, pre-commit hooks, adding a new model.