Deploy a Slurm Cluster
1
Boot cluster with shared storage and Slurm orchestrator
Navigate to the Multi-Node Cluster tab and select a cluster configuration with shared storage attached. Choose Slurm as your orchestrator during the deployment process.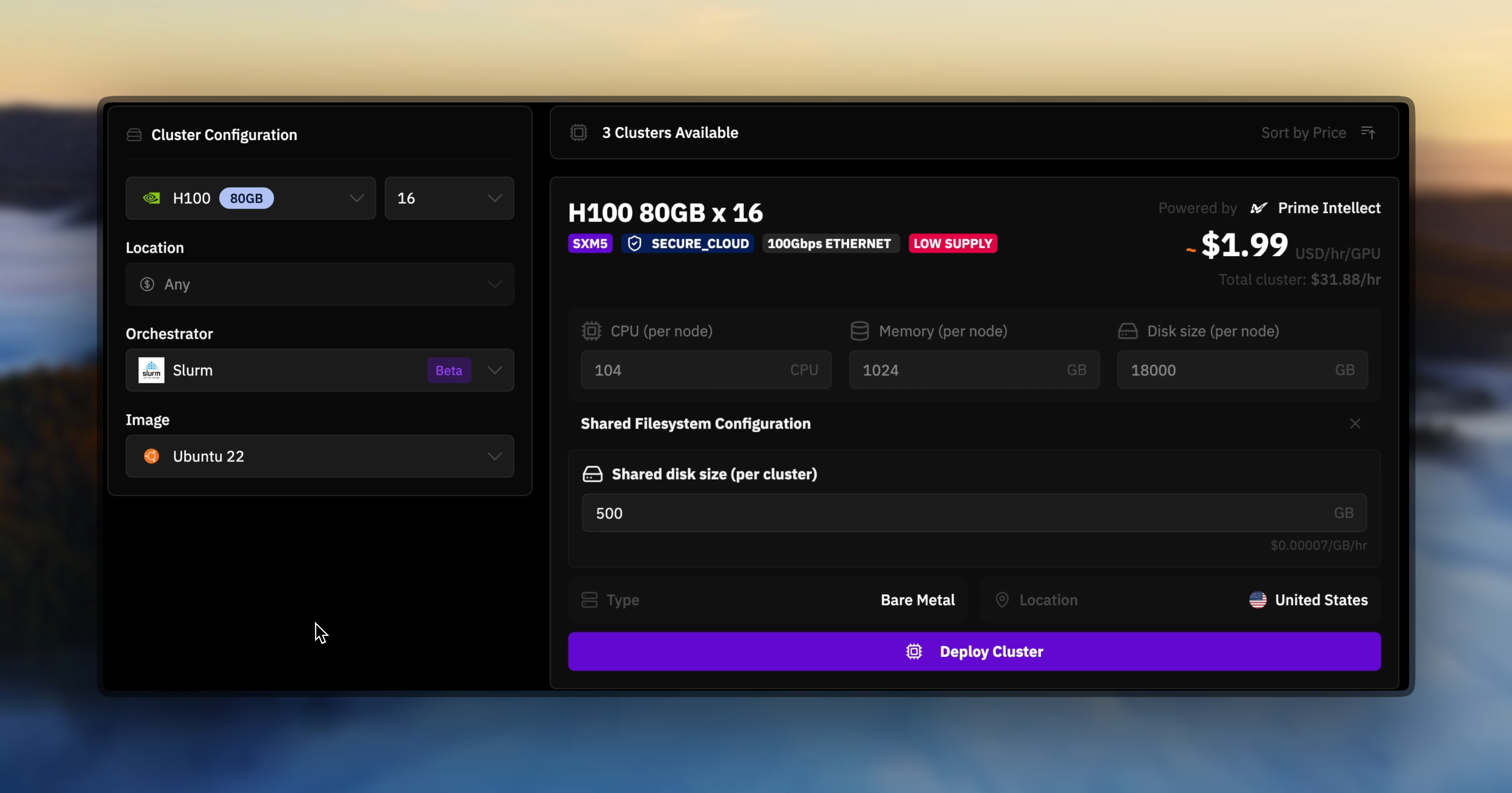
2
Access the controller node
Once the cluster is deployed, the UI displays the controller IP address. Always connect to the controller node to issue Slurm commands - this is your main management interface for the entire cluster.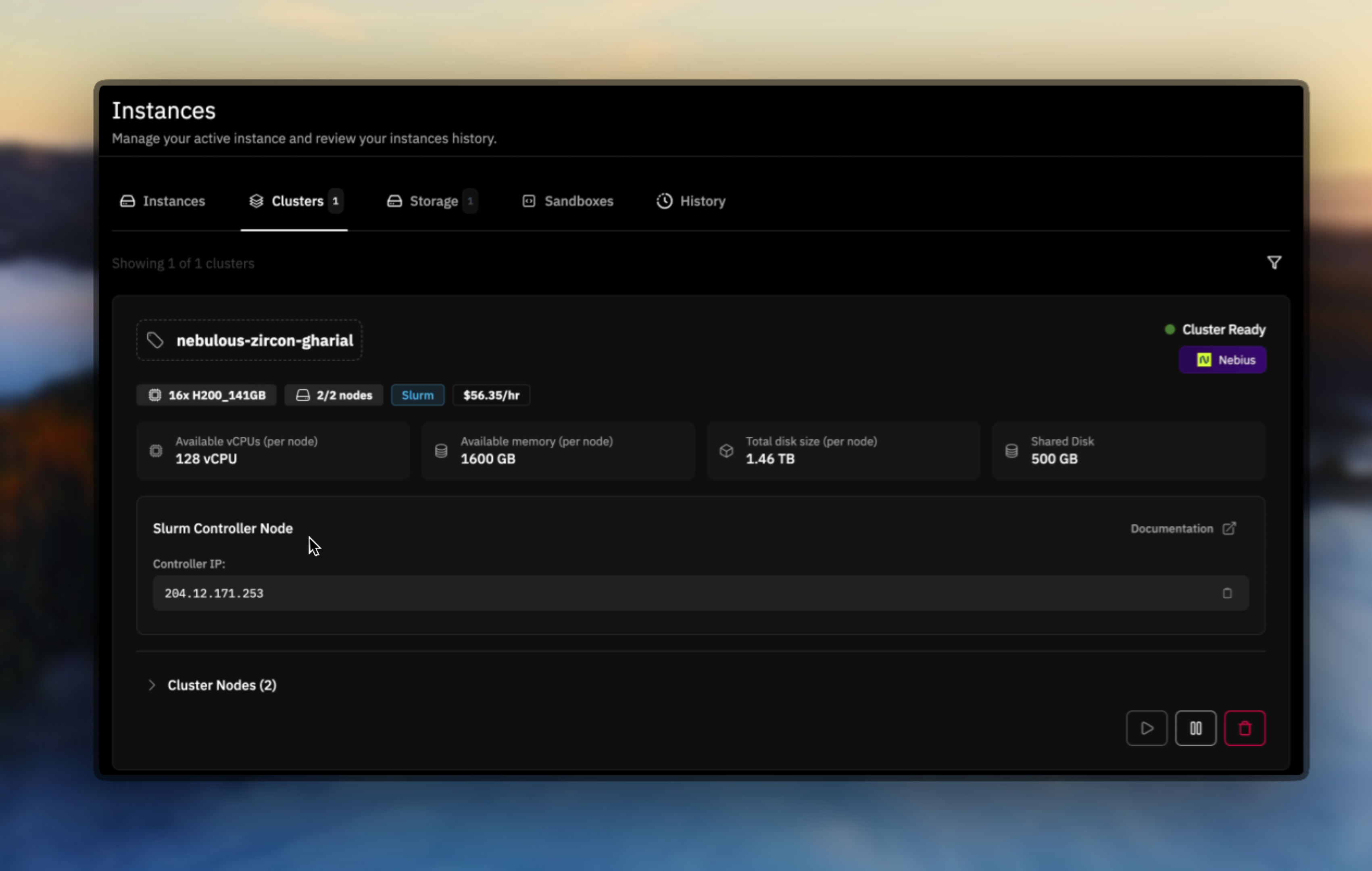
3
Verify cluster status
After connecting to the controller, verify your Slurm cluster is properly configured and all nodes are available.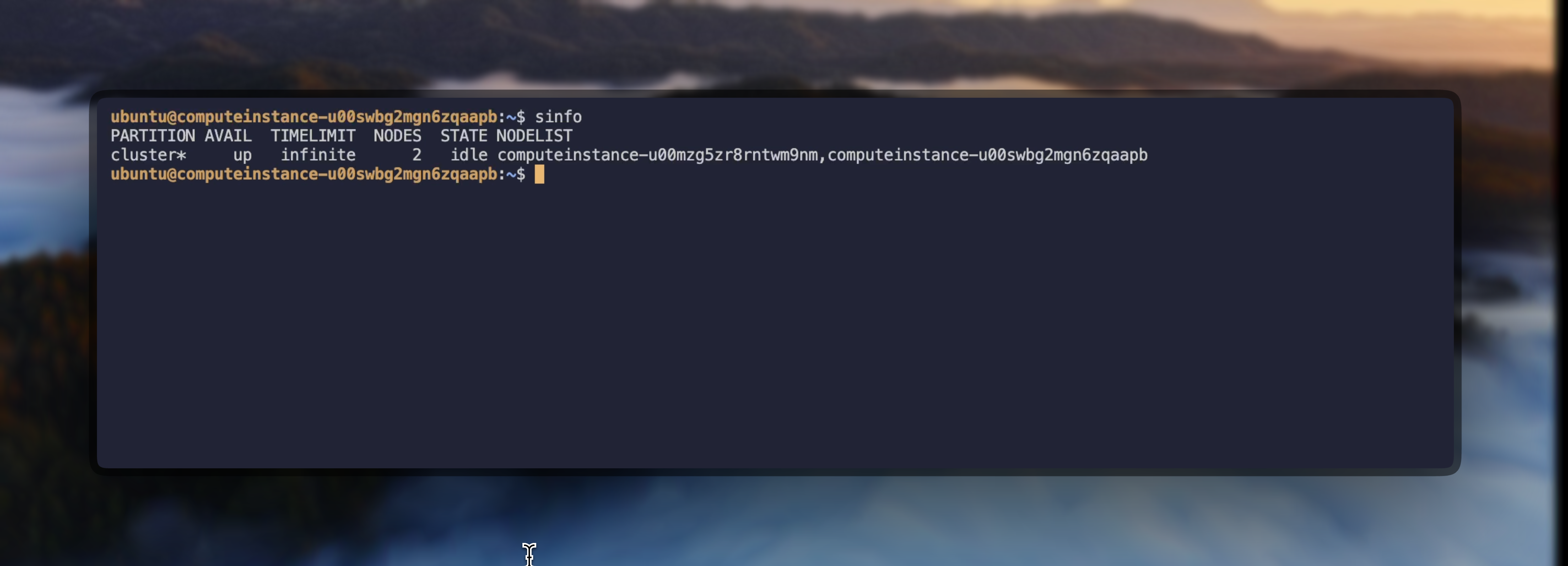
Essential Slurm Commands
Once connected to the controller node, you can use these Slurm commands to manage your cluster:View Cluster Information
GPU Resource Allocation
Prime Intellect clusters use the Generic Resource (GRES) system for GPU allocation. Understanding the correct syntax is crucial for successful job submission.Interactive GPU Sessions
When writing batch scripts, always use
--gres=gpu:N instead of --gpus-per-node=N to avoid InvalidAccount errors.Batch Job Submission
Batch jobs allow you to queue work that runs without manual intervention. Create a script file (e.g.,job.sh) with SBATCH directives:
Basic GPU Job Script
Submit and Manage Jobs
Job Output Location
Example: Quick Cluster Test
Verify your Slurm cluster with these simple tests:Troubleshooting Common Issues
InvalidAccount Error
If you encounterInvalidAccount errors when submitting batch jobs:
- Use correct GPU syntax: In batch scripts, always use
--gres=gpu:Ninstead of--gpus-per-node=N - No accounting plugin: Prime Intellect clusters intentionally don’t use Slurm’s accounting plugin since clusters are single-tenant with dedicated resources. Remove any
#SBATCH --account=directives from your scripts - Check partition availability: Ensure the partition you’re requesting exists with
sinfo
Prime Intellect clusters run without the Slurm accounting plugin because each cluster is single-tenant with dedicated resources. This simplifies configuration and eliminates account-based resource restrictions, giving you full access to all allocated resources without quota management overhead.
Incorrect (causes InvalidAccount)
Correct
Job Output Not Found
If you can’t find your job output files:- Check working directory: Output files are created where
sbatchwas run - Use absolute paths: Specify full paths in
--outputand--errordirectives - Check other nodes: If submitted from a compute node, outputs may be on that node’s local storage
- Always submit from shared storage: Change to the shared storage directory before running
sbatch
Node Communication Issues
If nodes can’t communicate or jobs hang:- Verify all nodes are in
idlestate withsinfo - Check node connectivity:
srun --nodelist=<node> hostname - Ensure shared storage is mounted on all nodes
- Consider restarting your cluster if issues persist
Advanced Slurm Commands
Direct Node Access
Access specific compute nodes directly for debugging or monitoring:Resource Monitoring
Job Arrays for Parameter Sweeps
Run multiple similar jobs with different parameters:Environment Variables
Useful Slurm environment variables available in jobs:Shared Storage Integration
Your Slurm cluster comes with shared storage automatically mounted on all nodes. The UI displays the mount path for your shared storage directory. This ensures:- Consistent file access across all compute nodes
- No need to manually copy data between nodes
- Simplified job submission and management
- Persistent storage for checkpoints and results
Best Practices
Use the Controller Node
Always submit jobs and run Slurm commands from the controller node, not compute nodes
Leverage Shared Storage
Store your code, data, and outputs in the shared storage directory shown in the UI for seamless access across nodes
Monitor Resources
Regularly check cluster utilization with
sinfo and squeue to optimize job schedulingUse Job Arrays
For parameter sweeps or similar tasks, use Slurm job arrays for efficient scheduling