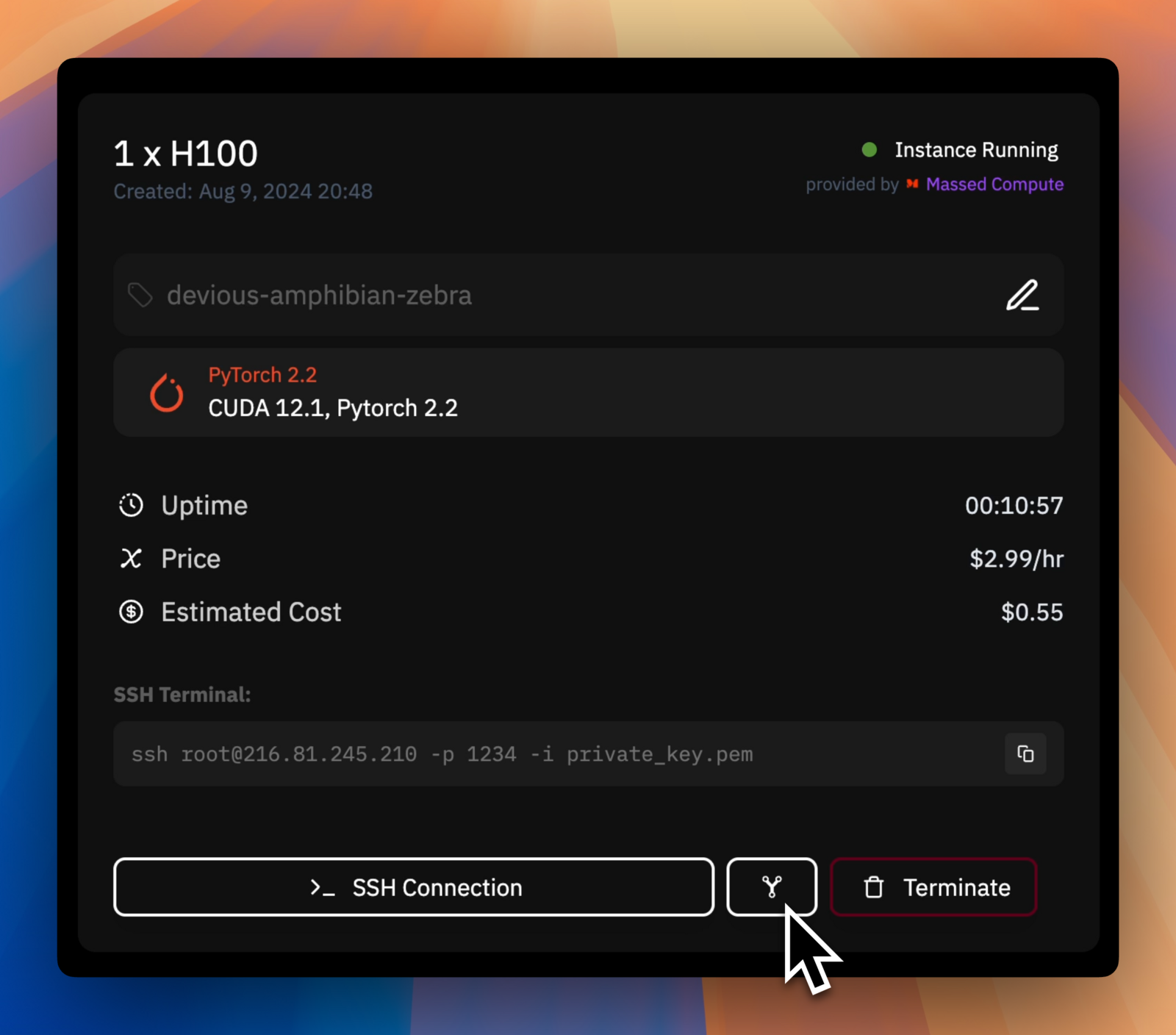
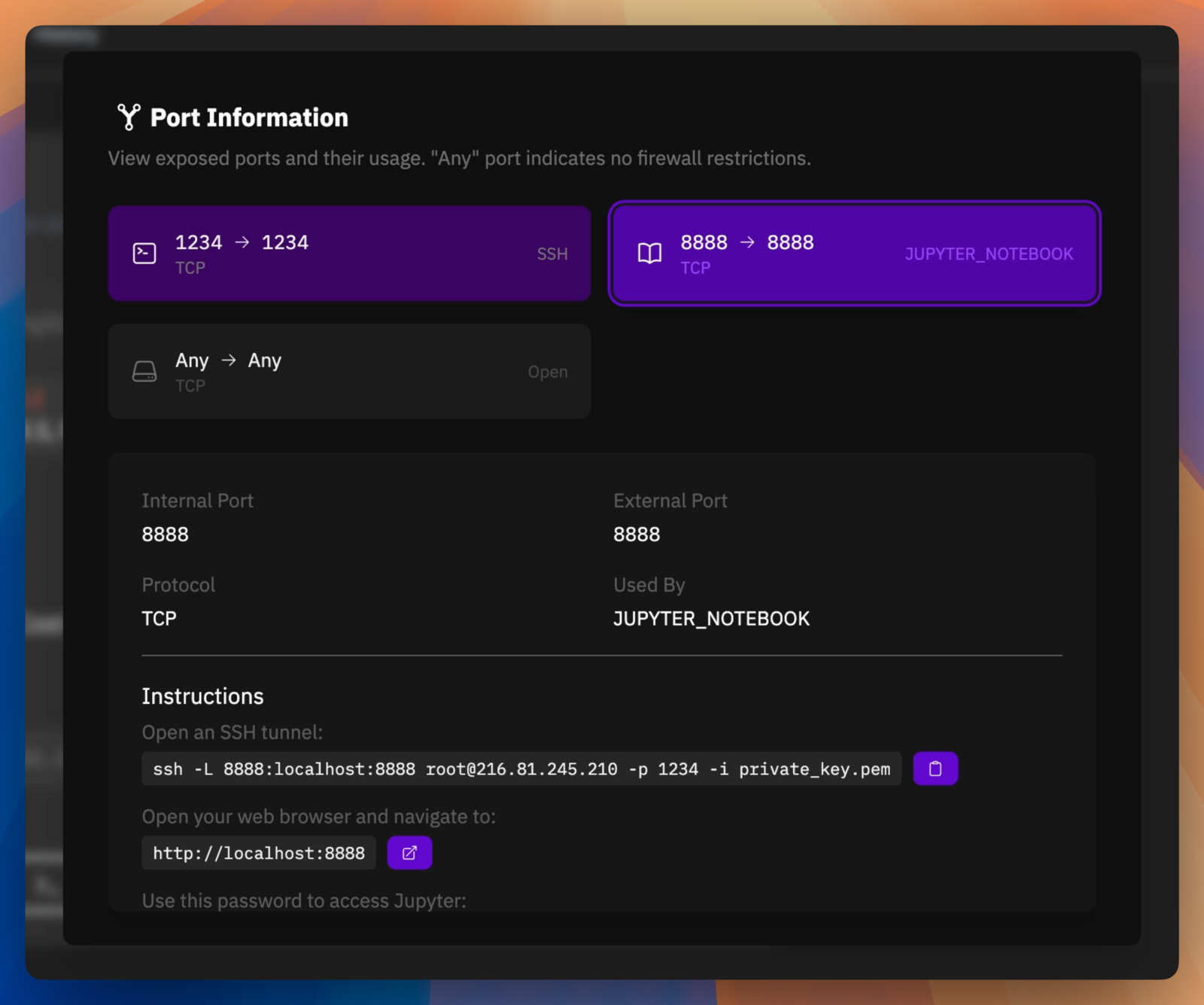
Deploy your private API instance of Llama3.1 via the VLLM inference library.
Select one of the pre-configured Llama VLLM
Deploy your GPU instance and wait until the installation process is complete
Click our Port Information Button
Follow the Instructions to connect to your Jupyter Notebook