Getting Started
1. Get Your API Key
First, obtain your API key from the Prime Intellect Platform:- Navigate to your account settings
- Go to the API Keys section
- Generate a new API key with Inference permission enabled
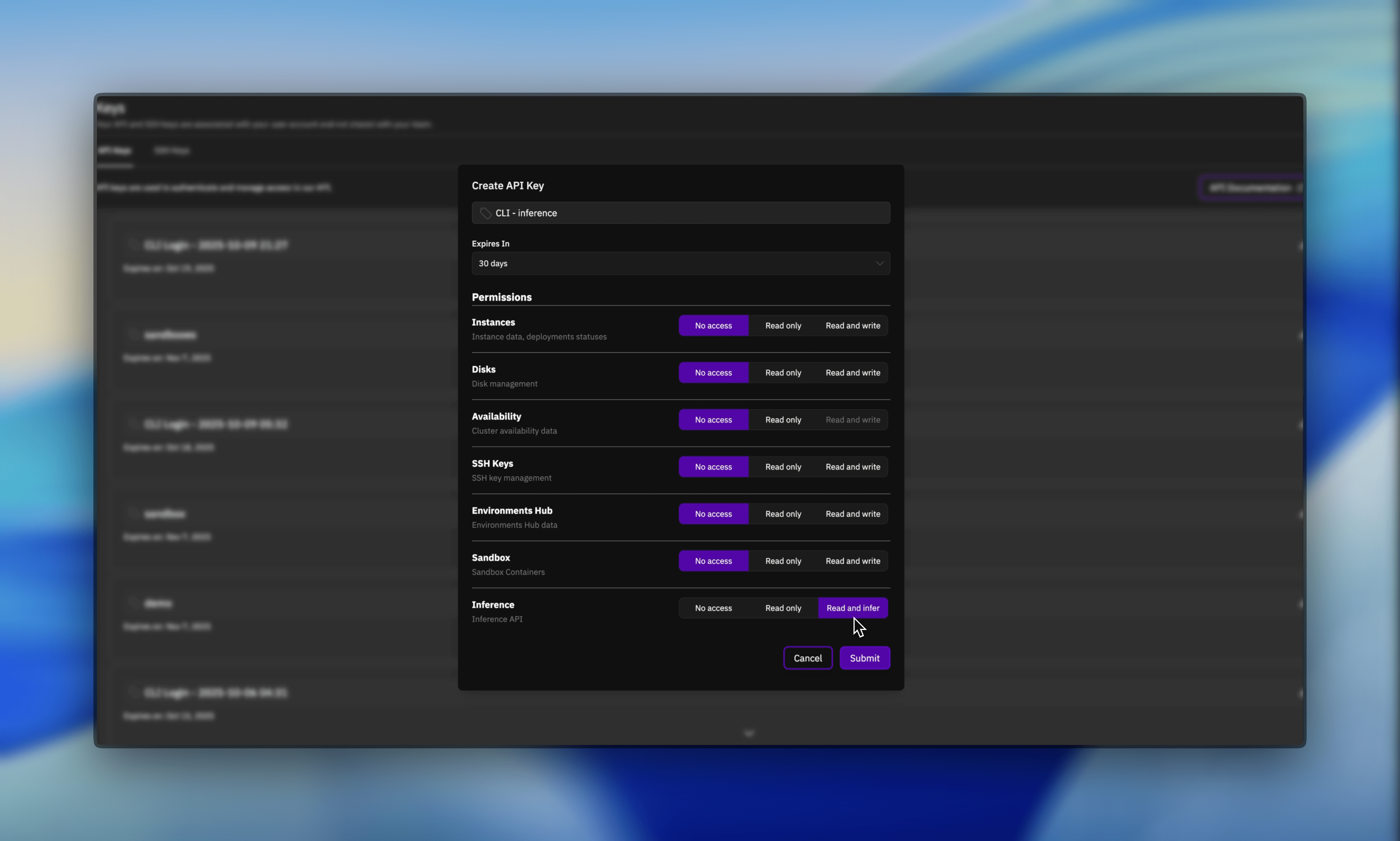
2. Set Up Authentication
Set your API key as an environment variable:3. Access through the CLI or API
You can use Prime Inference in two ways:Prime CLI (Recommended for Evaluations)
The Prime CLI provides easy access to inference models, especially useful for running evaluations:For evaluations: See Environment Evaluations guide for comprehensive examples and best practices regarding evaluations.
Direct API Access (OpenAI-Compatible)
Team accounts: Include the
X-Prime-Team-ID header to use team credits instead of personal account. Find your team ID via prime teams list or on your Team Profile page.Available Models
Prime Inference provides access to various state-of-the-art language models. You can list all available models using the models endpoint:Get All Available Models
Pricing and Billing
Prime Inference uses token-based pricing with competitive rates:- Input tokens: Charged for tokens in your prompt
- Output tokens: Charged for tokens in the model’s response
- Billing: Automatic deduction from your Prime Intellect account balance
Viewing Your Inference Usage
Track your inference usage and billing on the Billing Dashboard under the Inference tab: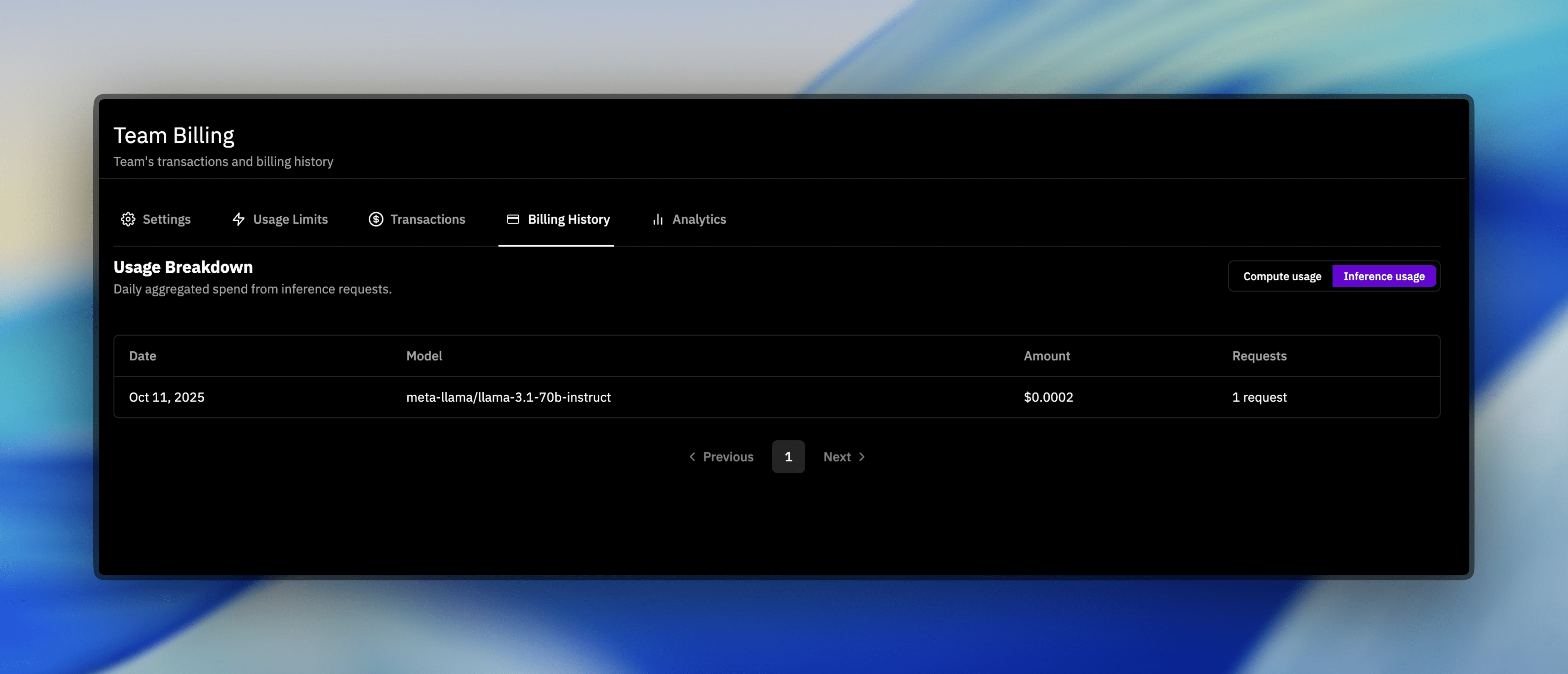
Next Steps
Advanced Usage
Streaming responses, advanced parameters, and more examples
Team Accounts
Using inference with team accounts and managing team billing
Troubleshooting
Fix common inference errors, including insufficient funds and team billing context
Environment Evaluations
Primary use case: Learn how to run model evaluations using
prime env eval with inference modelsInference API Reference
Detailed documentation for models and chat completion endpoints